Thursday, April 25, 2013
Thursday, April 11, 2013
Out of This World Images
Oh, you thought I was talking about cats? No, when I say "out of this world", I mean it literally.
Through the Hubble Legacy program, NASA makes available the raw data captured by one of human kinds greatest achievements. (Well, I think the Hubble Space Telescope is one of our greatest achievements anyway.)
Unfortunately, you won't find JPEG files on the site, but rather a somewhat exotic format called "fits". I'll spare you the details on what exactly a .fits file is, but suffice it to say, it stores a lot of information. Just one channel of the image of galaxy M51, the galaxy used as an example in this article, is almost three hundred megabytes.
Here, I want to take a brief look at working with these images, and how you can create original spacescapes with real data. It's a great way to spruce up any space themed design, plus, you get the geek cred that comes with being able to say you've messed with the same raw data as NASA scientists.
If you'd like to follow along, head on over to the Hubble Legacy Archive, and download an image of your choice. I recommend looking for galaxy M51, because it's easy to find some very high quality images.
You'll also need software appropriate for handling .fits files. You'll need to research what is good for your platform, I'm a Linux user, so I'll be using ImageMagick. Now, some common programs such as GIMP can actually open the .fits files directly, but they can't handle the ultra-high bit depth of the files. I recommend ImageMagick because it properly supports arbitrary bit depth file operations. (Yes, arbitrary bit depth.)
When you first open the .fits file, it is likely to appear black. That's OK, it's just because there is very low light data. The sensor on the Hubble is designed to be sensitive enough to pick up light from distant stars, and also robust enough to view much nearer objects like, say, the sun.
In ImageMagick, I use the Stretch Contrast function to fix the exposure into something that makes visual sense. Once you're happy with the exposure, save the image out to a file.
Through the Hubble Legacy program, NASA makes available the raw data captured by one of human kinds greatest achievements. (Well, I think the Hubble Space Telescope is one of our greatest achievements anyway.)
Unfortunately, you won't find JPEG files on the site, but rather a somewhat exotic format called "fits". I'll spare you the details on what exactly a .fits file is, but suffice it to say, it stores a lot of information. Just one channel of the image of galaxy M51, the galaxy used as an example in this article, is almost three hundred megabytes.
Here, I want to take a brief look at working with these images, and how you can create original spacescapes with real data. It's a great way to spruce up any space themed design, plus, you get the geek cred that comes with being able to say you've messed with the same raw data as NASA scientists.
If you'd like to follow along, head on over to the Hubble Legacy Archive, and download an image of your choice. I recommend looking for galaxy M51, because it's easy to find some very high quality images.
You'll also need software appropriate for handling .fits files. You'll need to research what is good for your platform, I'm a Linux user, so I'll be using ImageMagick. Now, some common programs such as GIMP can actually open the .fits files directly, but they can't handle the ultra-high bit depth of the files. I recommend ImageMagick because it properly supports arbitrary bit depth file operations. (Yes, arbitrary bit depth.)
When you first open the .fits file, it is likely to appear black. That's OK, it's just because there is very low light data. The sensor on the Hubble is designed to be sensitive enough to pick up light from distant stars, and also robust enough to view much nearer objects like, say, the sun.
In ImageMagick, I use the Stretch Contrast function to fix the exposure into something that makes visual sense. Once you're happy with the exposure, save the image out to a file.
Thursday, April 4, 2013
Tuesday, March 19, 2013
Wednesday, March 6, 2013
Tuesday, February 26, 2013
How to set up a LAMP
LAMP is the common acronym for Linux, Apache, MySQL, PHP/Perl. It reflects one of the most common web server setups in use today. I've set up LAMP servers enough times now that I've mostly got it down to a science, and I'd like to share with you how I set up a LAMP.
sudo apt-get update; sudo apt-get install apache2 php5 mysql-server openssh-server postfix proftpd-basic phpmyadmin phpsysinfo php5-gd php5-curl php5-suhosin php5-sqlite; sudo a2enmod userdir; sudo a2dismod cgi deflate;
Choosing the "L"
I use the latest Ubuntu LTS, or Long-Term-Service release. This ensures 6+ years of compatibility, stability, bug fixes, and security fixes. CentOS, Red Hat Enterprise Linux, and Debian Stable are other common choices, but for the purposes of this document, I will assume Ubuntu 12.04.Basic "A"
The "A" in LAMP is for the Apache web server, and there's really not much choice in that. Make sure you're running a current version, though. You may also choose which modules to enable or install. I try to keep the server light, and I disable CGI and and deflate. You can enable CGI if you need Perl, or enable Deflate to save bandwidth, but I tend to target script performance and load handling over bandwidth. I also use mod_userdir, which you should install if given the option. On Ubuntu, all of these mods come along with the basic apache2 package.
"M" and "M" (and occasionally another "P")
Although PostgreSQL is also a fantastic option, MySQL is still the de facto standard for LAMP stacks. Future versions of Red Hat Enterprise Linux and Ubuntu LTS will switch to the completely compatible fork, MariaDB, and will keep the acronym neatly in tact. MySQL's InnoDB database
engine is nearly ACID compliant, fast, and featureful. For this reason, I install MySQL 5.5 or higher for now, and will use MariaDB when it is widely available. I also often install PHPMyAdmin along with MySQL.
Mind your "P" (or "R" or "L" or...)
The last letter(s) in LAMP are the most flexible. PHP is a common choice, but so was Perl (thankfully, not so any more, though you might still need it with CGI), and Python, Ruby, Lisp, and a few others are also gaining in popularity. I'll focus on PHP, since it's what I mostly develop in, and it is what many common software projects such as WordPress, Drupal, and PHPBB are built on. PHP has a lot of libraries built in, but I recommend adding GD, CURL, and SQLite support which are often packaged separately. Most distributions package the Suhosin (security hardening) patch by default, if not, I recommend you install it as well.
Sending eMail
On Linux, getting PHP configured to send eMail is easy. Simply install Postfix, and you're on your way. During installation, you'll be asked for SMTP configuration, so make sure you have that handy.
Accessing the Server
The standard methods of interacting with a web server are SSH, FTP, and SFTP. I recommend ProFTPd and of course the standard SSH server. ProFTPd is my FTP server of choice because it is very easy to set up. You log in with your system account, and your permissions are determined by what they are set as on the server. This makes it secure and easy to configure all in one.
The Magic Command
One of the things I love about setting up Linux servers is that you can get it down to just a few commands. As my parting thought, here's a magical command for Ubuntu flavored servers that will get you up and running in one go.
sudo apt-get update; sudo apt-get install apache2 php5 mysql-server openssh-server postfix proftpd-basic phpmyadmin phpsysinfo php5-gd php5-curl php5-suhosin php5-sqlite; sudo a2enmod userdir; sudo a2dismod cgi deflate;
Tune in next time for how to set up user accounts, access control, per-user websites, DNS integration, and performance tuning for Apache!
Sunday, February 10, 2013
The Importance of Normalcy
In most cases, I champion being unique, and in most cases, that means not being normal. In the case of databases, however, that isn’t the case. In the lingo of database land, being Normal is to be Unique.
In the earliest times, the idea of a database was primitive. If you even had something called a database, it didn’t look much like our databases today. For the most part, programs stored their information in clever flat-file structures. Let’s imagine that you wanted a list of employees at a company. Some are developers, others are managers, some are in the Android department, some in the iOS department, some in the design department, and some in the web development department. An early application might have treated this data as a fancy sort of CSV -- merely separating each of the employee’s fields with a delimiter.
While this works fine for smaller numbers of people, you begin to encounter severe performance problems when you want to manipulate the data based on certain fields. At first, this isn’t a problem. Finding all the people who work under a manager as as simple as matching the “manager” field to the manager’s name. Of course, the wacky new employee (Moreena) who decided to enter their manager’s name as “Kymberlie” instead of “Kimberly” isn’t going to show up. It would make things simpler if the system instead showed options for existing managers so that Moreena can simply select her manager from a list. Generating a list of all existing managers now requires scanning every existing record in the document, a time consuming operation.
Eventually, a new concept, the relational database, was born. Enter: Normalcy. A relational database was so called because it took these spreadsheet like structures, called them tables, and allowed you to specify relationships between them. Along with this came the concept of normalization, meaning that the database was structured in such a way that data was repeated as little as possible, and organized in a way that was as efficient as possible.
If we return to our example earlier, we would no longer store each employee as a single record with all of the information; at least, not exactly. Since multiple people work for the same manager, that manager’s name is duplicated data. We then take that data and “Normalize” it, by putting it in a separate table. The same is true of departments. Each table gets a special column called a primary key. This key is a unique internal way to identify each item. By convention, this is called the “id”. What’s important is that the unique key is internal to the database, and is linked but not equivalent to the actual text. To associate an employee with a manager and with a department, we define two fields for each employee which are a special type called a foreign key which points to the identification column in the table with the information we want to associate. There is now a simple, concise, table which lists the company’s managers, one of whom is Kimberly. When Moreena goes to select a manager, the database no longer needs to scan an entire document. Instead, it simply lists the small list of managers, and when she selects Kimberly from the list, inserts the unique identifier into her manager field as a foreign key, directly linking her to her manager in an efficient way.
Keeping your databases normalized is absolutely important both because it improves the efficiency of your queries, and also because it maintains the integrity of your data. Given our example, if Kimberly decides that she actually likes the way Moreena spelled her name, and gets it legally changed, it would be difficult to apply this to a monolithic structure. It would require the equivalent of a massive find-and-replace operation. Of course, that may result in Kimberly-the-housekeeper who takes out the trash getting her name changed as well. In a normalized database, since only the unique internal identifier links the manager to the employee, you can simply change the manager’s name, and leave the id the same. Thus, the next time it lists your manager, it shows the new name, as referenced by the id. Additionally, modern databases provide functions that further speed up queries on normalized data, allowing even a moderately powerful server to handle literally millions of data elements and return complex queries in a fraction of a second.
Early Databases
In the earliest times, the idea of a database was primitive. If you even had something called a database, it didn’t look much like our databases today. For the most part, programs stored their information in clever flat-file structures. Let’s imagine that you wanted a list of employees at a company. Some are developers, others are managers, some are in the Android department, some in the iOS department, some in the design department, and some in the web development department. An early application might have treated this data as a fancy sort of CSV -- merely separating each of the employee’s fields with a delimiter.
While this works fine for smaller numbers of people, you begin to encounter severe performance problems when you want to manipulate the data based on certain fields. At first, this isn’t a problem. Finding all the people who work under a manager as as simple as matching the “manager” field to the manager’s name. Of course, the wacky new employee (Moreena) who decided to enter their manager’s name as “Kymberlie” instead of “Kimberly” isn’t going to show up. It would make things simpler if the system instead showed options for existing managers so that Moreena can simply select her manager from a list. Generating a list of all existing managers now requires scanning every existing record in the document, a time consuming operation.
The Relational Revolution
Eventually, a new concept, the relational database, was born. Enter: Normalcy. A relational database was so called because it took these spreadsheet like structures, called them tables, and allowed you to specify relationships between them. Along with this came the concept of normalization, meaning that the database was structured in such a way that data was repeated as little as possible, and organized in a way that was as efficient as possible.
If we return to our example earlier, we would no longer store each employee as a single record with all of the information; at least, not exactly. Since multiple people work for the same manager, that manager’s name is duplicated data. We then take that data and “Normalize” it, by putting it in a separate table. The same is true of departments. Each table gets a special column called a primary key. This key is a unique internal way to identify each item. By convention, this is called the “id”. What’s important is that the unique key is internal to the database, and is linked but not equivalent to the actual text. To associate an employee with a manager and with a department, we define two fields for each employee which are a special type called a foreign key which points to the identification column in the table with the information we want to associate. There is now a simple, concise, table which lists the company’s managers, one of whom is Kimberly. When Moreena goes to select a manager, the database no longer needs to scan an entire document. Instead, it simply lists the small list of managers, and when she selects Kimberly from the list, inserts the unique identifier into her manager field as a foreign key, directly linking her to her manager in an efficient way.
Being Normal
Keeping your databases normalized is absolutely important both because it improves the efficiency of your queries, and also because it maintains the integrity of your data. Given our example, if Kimberly decides that she actually likes the way Moreena spelled her name, and gets it legally changed, it would be difficult to apply this to a monolithic structure. It would require the equivalent of a massive find-and-replace operation. Of course, that may result in Kimberly-the-housekeeper who takes out the trash getting her name changed as well. In a normalized database, since only the unique internal identifier links the manager to the employee, you can simply change the manager’s name, and leave the id the same. Thus, the next time it lists your manager, it shows the new name, as referenced by the id. Additionally, modern databases provide functions that further speed up queries on normalized data, allowing even a moderately powerful server to handle literally millions of data elements and return complex queries in a fraction of a second.
Monday, February 4, 2013
Principles of UX Design
All the time we hear about making things pretty. We also still hear a lot of complaints. This time, I want to approach the problem from a different perspective. Instead of talking about user interface design, I want to talk about user experience design. This isn't about how websites look, it's about how websites work.
In this case, not an overview of this article, but rather, how to think about the overview of a user interface. A good user experience is action-oriented. Ask yourself, "what does the user want to do?". If, for example, the answer is "write something", that task should take center stage. You should also ask, "what does the user want to avoid". In the case of writing something, that is most often "distraction". Blogger and WordPress are two very polished user interfaces for writing, but I've never been too fond of WordPress's user experience.
 Whether or not, and how to confirm performing an action with a user is always a question to ask. Often, that comes down to whether or not the action is able to be undone. Even a delete, if not permanent, is not something that you need to confirm. Almost all the time, a user means to do what they are indicating, and asking every time is just an annoyance. If you must confirm each action, make it as easy as possible for the user. One way I have done this is to pop up a small dialog with large buttons directly under the cursor. In this way, the target to confirm is easy to hit, and doesn't require a lot of mouse movement. Another way to approach the problem is to simply make it difficult for the user to make a mistake. When managing users, there are various actions that can be performed per account. I use a UX that makes it a simple and consistent two-step process. First, the administrator selects the account they wish to perform the action on. The account is highlighted, making it easy to see what account is selected. The buttons to edit and delete are large, separated, and easy to differentiate. Deleting is a simple and quick process, but it still requires two clicks.
Whether or not, and how to confirm performing an action with a user is always a question to ask. Often, that comes down to whether or not the action is able to be undone. Even a delete, if not permanent, is not something that you need to confirm. Almost all the time, a user means to do what they are indicating, and asking every time is just an annoyance. If you must confirm each action, make it as easy as possible for the user. One way I have done this is to pop up a small dialog with large buttons directly under the cursor. In this way, the target to confirm is easy to hit, and doesn't require a lot of mouse movement. Another way to approach the problem is to simply make it difficult for the user to make a mistake. When managing users, there are various actions that can be performed per account. I use a UX that makes it a simple and consistent two-step process. First, the administrator selects the account they wish to perform the action on. The account is highlighted, making it easy to see what account is selected. The buttons to edit and delete are large, separated, and easy to differentiate. Deleting is a simple and quick process, but it still requires two clicks.

Overview
In this case, not an overview of this article, but rather, how to think about the overview of a user interface. A good user experience is action-oriented. Ask yourself, "what does the user want to do?". If, for example, the answer is "write something", that task should take center stage. You should also ask, "what does the user want to avoid". In the case of writing something, that is most often "distraction". Blogger and WordPress are two very polished user interfaces for writing, but I've never been too fond of WordPress's user experience.
 |
| Blogger |
 |
| WordPress |
Blogger is a Google product, so it retains the Google branding bar. WordPress provides something similar, but unlike Google, it is only one product, so why is it there? Google hides the left hand navigation, giving a wider area for writing, and places formatting buttons outside the writing area. Post settings are neatly organized in both, but Google hides them in an understated expandable menu. Even the icons gray, and each is formatted cleanly and consistently. I have no trouble blocking those blocks out when writing. WordPress mixes gradients, different control types, boxes, and a nice big blue button right next to where I'm writing. It's not terrible, but more distracting than the Blogger experience. Finally, I have to criticize the big pink dialog telling me a plugin is incorrectly installed. First of all, there's probably a good reason why the plugin is set up like it is, second, I'm not a user who has the required access to fix it, and third, even if I did, why do I care about it at all when I'm writing a new blog article? A simple, focused, and task-oriented UI will lead to the best user experience. Back to the idea of an overview, this means that a cursory glance over a page should immediately answer those same two questions for the user. If a user wonders "what am I expected to do here?" they should immediately be able to identify what it is, and a lack of distractions should keep them from adding "and I can do that here too..." to their answer.
To Confirm or Not To Confirm


UI vs. UX
Whether a design decision falls more in user interface or user experience is a fine line, and almost everything falls at least partially in both categories. There are many other aspects of the user experience to consider, and design is certainly something that plays a part. That said, pure user experience doesn't need to look pretty, it needs to be functional, and is a much more fundamental part of user interface creation than the design elements. As important as design is, I encourage you to always consider UX first, and then make it look nicer. Your users will appreciate it.
Wednesday, January 16, 2013
Javascript: Developing with State Machines
Usually when I develop a website, I do a lot server side. Servers are fast, PHP5 has some great Object Oriented qualities, and I can send only exactly as much data to the web browser as I need. That said, it isn't always the optimal way of doing things. Web apps rely on often massive amounts of JavaScript executing in the web browser to provide a smooth and seamless "app-like" experience.
For a recent project, my challenge was to display a list of data fetched from a server. Simple enough, but the first version was very procedural, and thus, difficult to maintain. If I wanted to "edit" an item in the list, it meant retrieving from some HTML element the information about the item, and then getting more information from the server, and kicking off a whole new procedure to create a UI of some sort to allow changes to the data. Unfortunately, ECMA Script, at least, out of the box, doesn't have strong Object Oriented support, so while it might be possible to treat each item as an object that seemed messy and relatively complicated.
Instead, I decided to use a State Machine, a decision that I will take a look at here.
Luckily, this simple prototype based model is also great for organizing anything, and it makes it ideal to create a state machine.
First, I need to store the machine state. toDoState will be a simple object with key-value pairs, each key representing a part of the machine state. For example, want to know what items are loaded into your state machine? toDoState.items can hold that information. When you click on one to select it, you need to set the state machine so that it knows, and you can do that by setting toDoState.selected. Determining what goes in to the state object is a bit tricky, but I tried to adhere to certain rules.
For a recent project, my challenge was to display a list of data fetched from a server. Simple enough, but the first version was very procedural, and thus, difficult to maintain. If I wanted to "edit" an item in the list, it meant retrieving from some HTML element the information about the item, and then getting more information from the server, and kicking off a whole new procedure to create a UI of some sort to allow changes to the data. Unfortunately, ECMA Script, at least, out of the box, doesn't have strong Object Oriented support, so while it might be possible to treat each item as an object that seemed messy and relatively complicated.
Instead, I decided to use a State Machine, a decision that I will take a look at here.
JavaScript and State Machines
First of all, JavaScript does have objects, they're just not the kind of objects you may be familiar with. A JS object is very simply a collection of keyed strings. Even a function in a JS object isn't much more than a string labeled as a function. Tell JS to print out myObject.myFunction, and you'll get the code, tell JS to print out myObject.myFunction() with the parenthesis at the end, and instead you'll get the result of executing the function. This simple object representation is very flexible, but very much unlike the rigid OO structure found in OO langages, by virtue of ECMA Script being a prototype language, not an object oriented one.Luckily, this simple prototype based model is also great for organizing anything, and it makes it ideal to create a state machine.
State Machines
At the most basic level, a state machine is a programming paradigm where a process is repeated, changing what it does based on the previous result. One way to do this, is to use a switch and a loop. Let's look at a stupid and far too simple function for validating an email address by checking that a string has (text)@(text).(text) .
function stateCheckEmail(emailAddress){
var state = 1;
for(var i=0; i<emailAddress.length; i++){
switch(state){
case 1:
if(emailAddress[i] != '@'){
state++;
}else{
state = 0;
}
break;
case 2:
if(emailAddress[i] == '@'){
state++;
}
break;
case 3:
if(emailAddress[i] != '@'){
state++;
}else{
state = 0;
}
break;
case 4:
if(emailAddress[i] == '.'){
state++;
}
break;
case 5:
if(emailAddress[i] != '.'){
state++;
}
break;
}
}
if(state == 6) return true;
return false;
}
-
The state machine, however, isn't enough of a paradigm for an entire project without needing to be expanded in some way.
- A state machine at its core is simply a way of saying, "I have an easily accessible variable or object that indicates the current state of my application."
- A state machine still requires some programming in the terms of functions.
- A state machine is a great concept, but it doesn't inherently provide a way to produce code like, say, an MVC paradigm.
First, I need to store the machine state. toDoState will be a simple object with key-value pairs, each key representing a part of the machine state. For example, want to know what items are loaded into your state machine? toDoState.items can hold that information. When you click on one to select it, you need to set the state machine so that it knows, and you can do that by setting toDoState.selected. Determining what goes in to the state object is a bit tricky, but I tried to adhere to certain rules.
- If the information can be used multiple times without needing to change or be reloaded, you can load it once into the machine state.
- Any item that can be "viewed" or "selected" should also be here.
- If something needs to be loaded from the server, do it once, and then only update it when needed.
- If possible, only update the specific part of the state object that has updated.
Next, I want to separate from the state machine reusable code, functions. To do this, I created a second object to work with the first, which I'll call toDoFunctions. I'll also hold to the same pattern convention as the state object. For example, since this is an AJAX powered list of To Do notes, I may need a function to retrieve the list of notes from the server. To reduce server calls, I want to get this into the state machine. Now, things start to come together.
toDoState.items = toDoFunctions.getItems();
Now, the items are part of the state of the machine. That might sound odd, but it makes more sense when we consider the third part of the extended paradigm.
When creating web pages, eventually, you need to generate HTML code. One of the biggest problems with creating HTML code on the fly, say, using jQuery, is that modifying that generated code is not nearly as easy as editing it if it's just HTML. This brings in to play the last part of the extended paradigm. This third object, I'll call it the "generator" will take care of producing pieces of HTML code. Each object will read the state of the machine and return the appropriate snippet of code based on the machine state. Now, having the list of items as part of the state makes sense, because if we call a function, say, toDoGenerator.itemsHTML(), it should return the HTML for the items that are in the state machine. This means if you delete an item, you just remove it from the toDoState.items object, call the generator function again, and this time you get back the HTML without the removed item, as it always reflects the current state.
Results
Creating a state machine for web apps with this extended paradigm has proved very useful to me. It makes it easy to manipulate the machine at any point, by simply changing the appropriate value in the states object, and allowing the code to execute as normal. It also makes it clear and concise to generate the HTML required for displaying the web app.Tuesday, January 8, 2013
Impact on the Go - Designing Mobile Websites
Earlier today, catching up on my daily Reddit, I came across an article comparing the different methods of building mobile websites over at Six Revisions. Mobile web development is something that I've been working on ever since I got my first smart phone, the Android powered Motorola Droid 1. The phone was relatively light on resources compared to the monsters we have today, and large websites loaded slowly, and made the phone crawl. When it came time to actually design a mobile website, though, I ran into problems. I thought "this is what CSS is for!", but mobile browsers didn't pick up on the "mobile" tagged style sheets, and so I needed a better solution. One option that was becoming popular at the time was to make some sort of mobile portal, like "m.omniimpact.com". Unfortunately, this is an SEO and content management nightmare. Finally, I settled on a hybrid approach, using a special PHP script that I wrote (you can find the oi_mobilesupport script on Github) to make sure that pages could be presented in a mobile-friendly manner, while not requiring duplication of content. Then, there came the responsive web design revolution.

 Responsive web design is a technique using CSS media queries to adapt the CSS on a website based on the width of the viewport. Now, some websites have embraced responsive design to fantastic effect. The Boston Globe is one of the best. The site displays all content in all view modes, fitting neatly to the size of the browser window. Resize even your desktop browser and watch the website adapt.
Responsive web design is a technique using CSS media queries to adapt the CSS on a website based on the width of the viewport. Now, some websites have embraced responsive design to fantastic effect. The Boston Globe is one of the best. The site displays all content in all view modes, fitting neatly to the size of the browser window. Resize even your desktop browser and watch the website adapt.
Unfortunately, the Boston Globe is somewhat unique in how well the technique actually works. Being a newspaper, the website is naturally text heavy. They can squeeze by with just one dominant image on the home page, and the rest being mobile-friendly sizes even on desktops. Although it is possible to make other types of websites scale, I often found responsive websites to exhibit the same problem I was trying to avoid in the first place; slow load times and poor performance.
The article from Six Revisions takes on the question of mobile web development techniques with great examples, clear pros and cons of each technique, and doing some actual timing of websites that use each of them. The convenience of non-duplicated data, the benefits to SEO, and significantly improved load times were all reasons that I always liked the hybrid approach and implement it in the websites that I create. I was pleased to see that same approach receive some oft-forgotten love from Six Revisions.
To give you a quick summary, the three major methods of creating mobile websites are dedicated mobile sites, responsive design, or a hybrid method, which often utilizes server-side browser detection. Dedicated mobile websites require a copy of the original data, can cause problems for search engine optimization if used incorrectly, often have difficulty redirecting users to the appropriate content on the other site, but they load quickly and can have highly tailored user interfaces. Responsive websites are often slow to load, difficult to make properly, and you are limited by what you can do with CSS, for example, adding or removing elements can be done, but requires all the elements to be loaded anyway, increasing load times. Responsive design also offers no option for the user to choose their preferred website experience. Hybrid design delivers a mobile-optimized version of the websites code, but utilizing browser detection instead of a different URL. When done properly, hybrid mobile website design provides the quick loading of a dedicated mobile site, without the data duplication or SEO nightmares. A good example of how hybrid design can take advantage of server side processing is presenting an alternate footer, as shown in the above screen shot. Note that on the mobile version, a fixed footer provides quick access links ( tel: and mailto: ) that will open the appropriate app on the user's phone. This code is used only when in mobile mode. On the other hand, the additional images used in the header are blocked on the mobile version, rendering the header with only text to speed load time.
To get the details, check out the full article article at Six Revisions.

 Responsive web design is a technique using CSS media queries to adapt the CSS on a website based on the width of the viewport. Now, some websites have embraced responsive design to fantastic effect. The Boston Globe is one of the best. The site displays all content in all view modes, fitting neatly to the size of the browser window. Resize even your desktop browser and watch the website adapt.
Responsive web design is a technique using CSS media queries to adapt the CSS on a website based on the width of the viewport. Now, some websites have embraced responsive design to fantastic effect. The Boston Globe is one of the best. The site displays all content in all view modes, fitting neatly to the size of the browser window. Resize even your desktop browser and watch the website adapt. |
| Responsive design at its best, the Boston Globe even supports the equivalent of tablet screens. |
Unfortunately, the Boston Globe is somewhat unique in how well the technique actually works. Being a newspaper, the website is naturally text heavy. They can squeeze by with just one dominant image on the home page, and the rest being mobile-friendly sizes even on desktops. Although it is possible to make other types of websites scale, I often found responsive websites to exhibit the same problem I was trying to avoid in the first place; slow load times and poor performance.
 |
| A refresh of the original design by another company, the updated website by Omni Impact now presents equivalent content instead of a limited mobile website. |
To give you a quick summary, the three major methods of creating mobile websites are dedicated mobile sites, responsive design, or a hybrid method, which often utilizes server-side browser detection. Dedicated mobile websites require a copy of the original data, can cause problems for search engine optimization if used incorrectly, often have difficulty redirecting users to the appropriate content on the other site, but they load quickly and can have highly tailored user interfaces. Responsive websites are often slow to load, difficult to make properly, and you are limited by what you can do with CSS, for example, adding or removing elements can be done, but requires all the elements to be loaded anyway, increasing load times. Responsive design also offers no option for the user to choose their preferred website experience. Hybrid design delivers a mobile-optimized version of the websites code, but utilizing browser detection instead of a different URL. When done properly, hybrid mobile website design provides the quick loading of a dedicated mobile site, without the data duplication or SEO nightmares. A good example of how hybrid design can take advantage of server side processing is presenting an alternate footer, as shown in the above screen shot. Note that on the mobile version, a fixed footer provides quick access links ( tel: and mailto: ) that will open the appropriate app on the user's phone. This code is used only when in mobile mode. On the other hand, the additional images used in the header are blocked on the mobile version, rendering the header with only text to speed load time.
To get the details, check out the full article article at Six Revisions.
Seven Years Ago; The Beginning of Omni Impact
Seven years ago, a student was putting away his materials after Spanish class. It was the last period of the day, and this student would prefer to take his time wrapping up and chatting with one of his favorite teachers instead of braving the masses of younger students in the overcrowded school. As the last of the materials from class went into the backpack, the frustrated typing of the teacher became apparent. A glance behind the student explained the cause; the teacher was trying to edit a website in one of the clumsiest systems he'd seen. "Señora? What kind of website is that?" he asked.
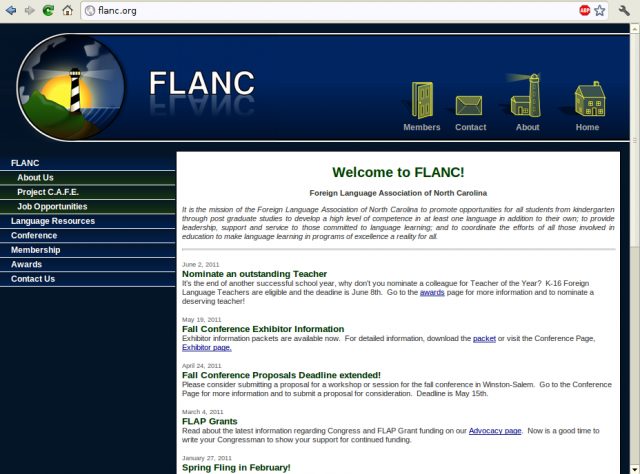 "It's for a non-profit organization I'm on the board of." was the reply, followed by "I'm sorry, though, I can't talk now, we need to update this page, and the software to do it is just awful."
"It's for a non-profit organization I'm on the board of." was the reply, followed by "I'm sorry, though, I can't talk now, we need to update this page, and the software to do it is just awful."
The student thought for a moment. "I might be able to help you."
This was the start of Omni Impact. I'm Daniel marcus, and seven years ago, I began work on my first major web development project. What began as a way to cut costs for a non-profit organization grew over the years into a full fledged content management system. Each year, hundreds of teachers log in to a platform that allows them to share files between each other, and stay in touch. Each year, I have improved my skills and widened my portfolio. Now, I look forward to sharing some of that experience with you through this blog.
The student thought for a moment. "I might be able to help you."
This was the start of Omni Impact. I'm Daniel marcus, and seven years ago, I began work on my first major web development project. What began as a way to cut costs for a non-profit organization grew over the years into a full fledged content management system. Each year, hundreds of teachers log in to a platform that allows them to share files between each other, and stay in touch. Each year, I have improved my skills and widened my portfolio. Now, I look forward to sharing some of that experience with you through this blog.
Subscribe to:
Posts (Atom)